


概要
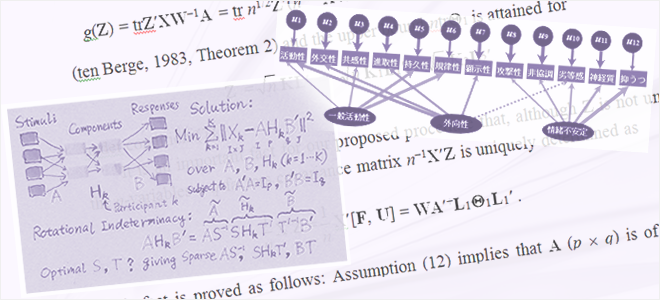
心理・行動科学データを分析するための統計解析法の開発、および、解析法の基礎理論の研究が主な研究テーマとなります。現在では特に、多変量解析法と総称される統計解析法、および、統計的因果推論のための方法論の研究開発を行っています。興味のある現象に対する統計数理モデルを考え、その解を得るための最適化アルゴリズムを構成することや、解の数理的性質を検討することなどが研究開発の重要な部分を占めます。
当研究室のWebサイトは現在リニューアル中です
現在のWebサイトには一部、古い情報が含まれている箇所があります。ご不明な点がありましたら、山本までお気軽にお問い合わせください。
お知らせ
| 坪田 (M2) が日本行動計量学会第52回大会 (2024年9月開催) で最優秀スチューデントポスター賞を受賞しました. | |
| 嶋田 (M2) が日本分類学会第42回大会 (2023年5月開催) で優秀学生発表賞を受賞しました. | |
| 学部3年生2名、修士1年生4名が新たに研究室に配属されました | |
| 瀬戸 (D1) が日本計算機統計学会第36回シンポジウムで学生研究発表賞を受賞しました。 | |
| 里村 (D3) による論文がFood Quality and Preferenceに掲載されました。 | |
| 山本 (准教授) が日本行動計量学会 林知己夫賞 (優秀賞) を受賞しました。 | |
| 瀬戸 (D1) が日本分類学会第41回大会 (2022年6月開催) で優秀学生発表賞を受賞しました。 | |
| 足立 (教授) が日本分類学会 論文賞を受賞しました。 | |
| 三田村 (M2) が日本分類学会 奨励賞を受賞しました。 | |
| 三田村 (M1) が日本分類学会第40回大会 (2021年7月開催) で学生優秀発表賞を受賞しました。 | |
| 伊藤(M1)がDSSV2019, Data Science, Statistics & VisualisationでOutstanding poster award[First Prize]を受賞しました. | |
| Yamashita & Adachiによる論文がJournal of Classificationに掲載されました. | |
| Yamashita & Adachiによる論文がMultivariate Behavioral Researchに掲載されました. | |
| 山本(M1)が2018年度日本分類学会シンポジウムで優秀学生発表賞を受賞しました. | |
| Cai Jingyu(M2)が日本分類学会第37回大会で学生研究発表賞を受賞しました。 | |
| Cai Jingyu(M1)が日本計算機統計学会第31回シンポジウムで学生研究発表賞を受賞しました。 | |
| 辻井(M1)が2017年度統計関連学会連合大会で優秀報告賞を受賞しました。 | |
| 山下(D1)がIMPS2017でStudent Travel Awardを受賞しました。 | |
| 辻井(M1)が日本計算機統計学会第31回大会で学生研究発表賞を受賞しました。 | |
| Li Ji Yao(M1)が第11回日本統計学会春季集会で学生優秀発表賞を受賞しました。 | |
| 2年生4名が研究分野に配属されました。 | |
| Li Ji Yao(M1)が日本計算機統計学会第30回シンポジウムで学生研究発表賞を受賞しました。 | |
| 足立(教授)が日本計算機統計学会の貢献賞を受賞しました。 | |
| 足立(教授)の著書「Matrix-Based Introduction to Multivariate Data Analysis」がSpringer社より出版されました。 |